You're running 2 tests a quarter because reaching significance takes 3 weeks.
CUPED variance reduction cuts time to significance by 20-40%. Run more tests on the same traffic.
 0.0on G2
0.0on G2Set up an A/B test without opening a ticket No deploy needed.
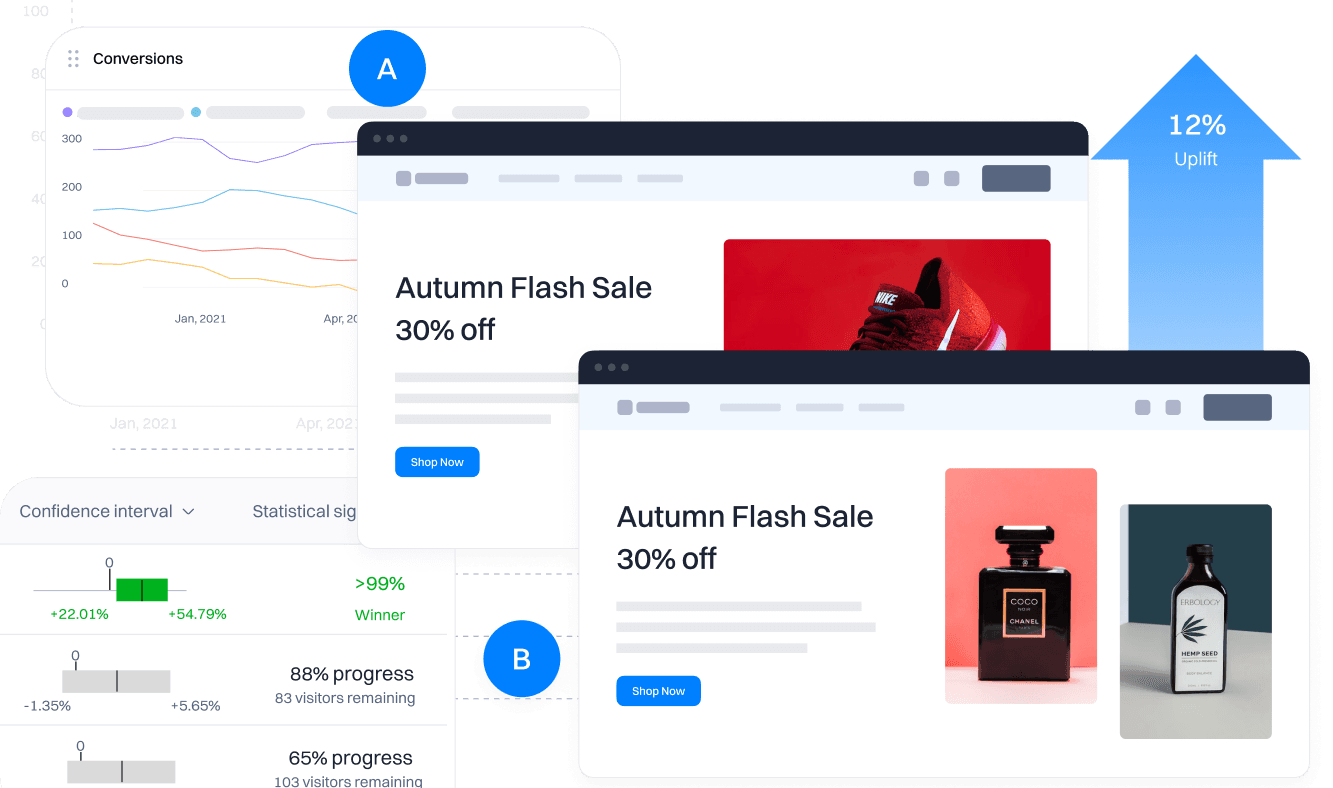
Change content, layout, copy, and logic directly on the page. The visual editor lets non-technical teams run experiments without waiting on engineering.
- No-code A/B and multivariate test setup on any page element
- Target by segment, acquisition source, plan type, or any behavioral attribute
- Preview variants before launching to confirm what each audience sees

Reach significance 3 weeks faster on the same traffic Same traffic, faster answer.
CUPED variance reduction uses pre-experiment behavioral data to cut the time you need to reach statistical significance by 20-40%. More experiments shipped. Fewer wasted weeks.
- CUPED reduces variance using each user's pre-experiment behavioral history
- Significance thresholds configurable per experiment - choose your acceptable risk
- Sequential testing support to monitor results without inflating false-positive rates

Test content, logic, and pricing - not just button color Go deeper.
Most A/B tools stop at the UI layer. Intempt experiments connect to product events, pricing logic, and backend feature flags so you can test what actually moves revenue.
- Test product flows, pricing tiers, and feature availability - not just copy and layout
- Behavioral events from your product trigger and measure experiment outcomes
- Winners promote directly to a Personalize rule in one click - no re-implementation

Connect every trusted source.
Plug into the tools your team already runs on.
Certified & Compliant





Your customer data stays yours, and stays secure.
The teams that made the switch

We were losing visitors before they signed up. Intempt's personalized experiences changed that - we started meeting people where they were instead of guessing. Once they're in, Intempt's automated email takes over and keeps the relationship moving. Acquisition and retention finally feel like one connected motion instead of two separate problems.
Jim Stromberg, CEO
StockInvest
Case Study
StockInvest needed to turn anonymous traffic into registered users before any retention strategy could work. With Intempt's Experiences, they personalized the anonymous visitor flow, surfacing the right content and CTAs to boost signup conversion. Once users signed up, automated Journeys nurtured them through onboarding and deeper engagement, steadily increasing lifetime value.
FAQ
Frequently asked questions
Everything you need to know about Intempt Experiments.
CUPED (Controlled-experiment Using Pre-Experiment Data) uses pre-experiment behavioral data as a covariate to reduce variance in your metric. The practical result: you reach statistical significance 20-40% faster on the same traffic. Instead of waiting 3 weeks for significance, most teams hit it in under a week.
Sources
* CUPED (Controlled-experiment Using Pre-Experiment Data) achieves 7-45% variance reduction depending on covariate selection. Deng et al. (Microsoft Research, 2013); Eppo, Statsig documentation (2024-2025).
Run 2 experiments a week, not 2 a quarter.
Connect your data source and your first experiment is live in the same session. CUPED is on by default - reach significance faster from day one.